
The Gullible Software Altruist
On corporate abuse of free and open-source software, particularly as it relates to GitHub's Copilot, and explaining why & how I began self-hosting my own code.

Earlier this month, I deleted all of my repositories on GitHub and cancelled my recurring monthly payment. In its place, I set up a server to host my Git repositories and an accompanying website for both private and public projects—in effect, providing my own private “GitHub replacement”.
This was made remarkably easy by a few tools (Digital Ocean, Gitea and Caddy). Later in this post, I’ll walk through—in rough detail—the basic steps I followed with these tools to accomplish this.
But first, let me answer the obvious question: Why? Why would I do such a thing? What about all of the stars on all of my repositories?! Why would I dare toss those into the wind?!
“Microsoft ♡ Open Source”
I’m too young to have directly experienced this—so forgive me if I get some details wrong—but in the late '90s, the United States Department of Justice conducted an investigation into Microsoft’s business practices, particularly as it pertained to Microsoft’s “operating system monopoly”, and how Microsoft was leveraging that monopoly in competition with Netscape (a now-mostly-forgotten competitor of Internet Explorer).
Long story short, it turns out a phrase was circling around Microsoft internally that captured their business goals in the browser space, among others—“embrace, extend, extinguish”. Microsoft was attempting to majorly disadvantage Netscape as a browser competitor through the following steps:
“Embrace”: Develop privately-sold software that conforms widely to a public standard or competing product
“Extend”: Introduce extensions or features that are not standardized, and thus not easily supportable by competitors, and use them to increase market share
“Extinguish”: Use increased market share as leverage to disadvantage competitors, solidifying market share
At the end of the day, none of this is terribly surprising—if you produced the kind of software that Microsoft does, you’d probably want to hinder competition too.
What’s more surprising is just how short-term the memory of so many programmers is. These programmers have seemingly imagined a fantasy land in which Microsoft is now totally-on-board with the Richard Stallman free software fairyland socialist utopia. Alternatively, maybe it’s simply the failure to propagate forward this “EEE” nugget of history. Or, perhaps, too many of the anti-corporate-power voices in computing have been bought off—or drowned out by those who are bought off—with nauseating, repetitive, embarrassing, corporate, social-political stunts. After all, a corporation’s power isn’t so bad if they rainbow-ify their logo for a month! Those who have been bought off by such nonsense will go on LARPing as part of the “resistance”—fighting for the “little guy”, for their “utopia”—unknowingly wearing the badge of the corporate-governmental American empire. This kind of brainwashed little “resistance soldier” has unfortunately become the norm within the computing world, and Microsoft couldn’t be happier.
For those not under the influence of this mind virus, we’ve all just had a wakeup call that Microsoft is not the awesome, friendly, totally-ethical corporation that we’ve been told they are—they remain an incompetent, bureaucratic, and exploitative corporation, operating many of the increasingly-scarce chokepoints (which I described here) within the computing ecosystem. This wakeup call started with a single, hilarious phrase:

This marketing was paired with a release of the Windows Calculator—yes, the brilliant Windows Calculator that everyone definitely-loves-to-use—which clocks in at an idiotic nearly-50,000 lines of code. That’s just the icing on the cake, though—there’s a darker reason for the hilarity of it all.
Yes, Microsoft, Of Course You ♡ Open Source
Imagine that you’re an organism that has evolved specifically for the purpose of consuming cake. You lack any human spirit—you don’t want to raise a family, build anything of value, or pursue something difficult and ambitious—you want to sit on your couch and eat cake.
You’ve somehow managed to find your way into a situation where your couch is situated within the Cakernet. The Cakernet is a place where chefs from all over the world come to bring free cake. They do this for great reasons—they’re trying to perfect their craft, share cake recipes with other chefs from around the world, and they’d like to feed starving children who need a free meal out of the kindness of their heart.
You’re a morbidly obese cake-consuming-organism (a heart attack is surely around the corner at any moment), so what’s best about this whole Cakernet situation is that your couch is situated right next to the place where everyone brings their cake. So, you know… it’s in your nature. You snag a cake or two.
So, as a cake-consuming-organism who has no other concerns in the world, the question is: Do you ♡ open cake at the Cakernet?
Of course you do.
It’s a silly and imperfect analogy, but it nevertheless illustrates the point. Giant technology corporations like Microsoft are not places for innovative industrial-strength engineering. They are places for bureaucrats, business-major project-managers, and H.R. employees. Freely-available open source software only prolongs their decay by providing them engineering hours that aren’t even on their payroll. They are the places where innovation goes to die—or, to be acquired and used as lifeblood.
CakeHub
That last part—acquisition and use for lifeblood—is precisely what became of GitHub after its acquisition by Microsoft in 2018.
GitHub recently announced its new Copilot feature. The feature, which costs $10 per month, uses an artificial intelligence “natural language → code” engine. That engine’s model is trained using publicly-available code on GitHub. Now, whether or not this feature is a good idea or not (it’s not), what is more important is that it uses this publicly-available code irrespective of the original author’s license.
Licenses have sometimes been a useful mechanism for those who want to share code and ideas with likeminded folks working in similar areas. They are, to some degree, able to prohibit use of such code and ideas in circumstances under which the author would want to be, for example, compensated.
By my personal experience in large corporations, I can attest to the fact that (at least some) corporations take code licenses quite seriously. A programmer working on a project for a large corporation—as I was told—shouldn’t even be reading code that is licensed under, for instance, GPL. In effect, absorbing information from that code and “repurposing” it in a new solution would constitute an intellectual property rights violation if not expressly permitted by the license.
For some reason, this concern for Microsoft disappears when it isn’t a human interpreting the code and repurposing it, but a less-human artificial intelligence model. It concerns them so little that they’ve decided to charge people for facilitating this exact process—even if their artificial intelligence engine were to produce line-for-line some of the code that was used to train it—without compensation to the original author of the training code—even if the original author had a license that required such compensation.
Does it stop being the original information at some point, simply because a data transformation was applied to it? If I ran the source code through an LZ compressor, and then losslessly decompressed it, did the data fundamentally change? What if it were a lossy compressor and decompressor? Furthermore, how does that differ from a human interpreting the code and using the information embedded within it? Is a human’s interpretation of code not simply compression, and their usage of that interpretation in producing new code not simply decompression?
For all of these reasons, it has become very clear to me that hosting code on GitHub means, ultimately, that you do not own it. I have no interest in spending thousands of hours of personal programming time on code that I don’t own for no compensation. I’ve already written before on the fact that all natural rights—the freedom to compute, the freedom to speak, the freedom to listen, the freedom to criticize authority—originate in the bedrock of natural rights, which is property ownership. When property ownership disappears, all natural rights do.
Open source code without respected licensing—especially that by small, independent developers who are just pursuing a side-project or a hobby—is little more than free, no-strings-attached labor. It sets ablaze any right to ownership you once had over your code.
It is difficult to succeed as an independent developer who cares about craftsmanship no matter what, because the market is unforgiving (as it perhaps should be)—it will be even more difficult to succeed if labor is freely given away for the benefit of large corporations who operate indefinitely as centralizing forces within the computing world.
Ultimately I find this truth rooted in the recent Internet-age cliché: If you’re getting something for free, it’s likely that you are—in some form or another—not the customer, but the product. This rings especially true in the case of those using GitHub as their version control hosting and sharing mechanism.
Closing The Gates To An Open Community
I’ve thrown many punches at many people in this post, but I’d like to affirm my love for the vision of open source software, despite my feelings that the open-source world as it exists is naïve and will ultimately lead us to a dark place.
I find the vision of freely trading ideas, techniques, and code appealing—I am passionate myself about sharing information and ideas, as I’ve attempted to do with my articles and formerly-public repositories. I want a world in which there is a strong population of craftsmen developers, who deeply care about the quality of their software, and who mentor each other to further pursue the limits of computing.
Unfortunately, throwing our code at publicly-accessible servers—freely providing our code to other independent developers, yes, but also large corporations—will not get us there.
With this post I’m advocating for a world in which code, information, and techniques are shared in pursuit of that vision, but only provided the explicit voluntary agreement of all involved parties.
One pathway to achieving this in some small way, I’d posit, is through a collection of private developer “circles” who don’t need to agree on anything or organize to any higher degree. Each circle would have full control over all related source code—it might be a single repository, a single project, or a collection of projects. These circles, then, can be moderated in the same way that a chat server can be moderated. Instead of only moderating spammers or nuisances, however, these circles can also have the ability to moderate corporate actors.
To that end, each circle can require a membership or access fee if they choose, with the price being non-uniform for all members. This ensures full-granularity control over distribution of source code. Large corporations may require a heftier license, and a kid in his room wanting to poke at a codebase—perhaps even contribute—may get in for free. Ultimately, all options are rooted in the owner’s voluntary action, which is where they should be.
GitHub’s Copilot has served as an excellent demonstration of the fact that licenses are just text—they’re simply magic “government scripts”—and they are only enforceable provided government enforcement and the depressingly slow process of proven injury in a court of law. What I’m advocating for is fully acknowledging the non-reality of licenses, in the same way that Microsoft has. Instead of drawing a line and saying people can’t cross it unless they pay a fee (a license), let’s build physical walls ourselves and physically enforce that people pay the fee.
I, for one, am tired of playing a game with imaginary rules that nobody else respects.
Those “physical walls” are built through self-hosting—getting valuable code off of centralized services like GitHub, and quickly under the control of closed developer circles.
One Approach To Self-Hosting
Unfortunately, self-hosting is a pretty huge pain—there is a reason why GitHub was preferable to me for all these years—and the whole experience needs some serious tender, love, and care. That being said, it has come a very long way due to a number of projects, tools, and services that people have done quite a remarkable job on. It was even doable for me—a self-hosting moron—in a matter of a day. Now, to be clear, I think the self-hosting experience could be trivial—the fully optimized experience would get you up-and-running in a few minutes—but a day is a small investment for an ownership-minded programmer who is about to spend 10,000 hours on his next project.
I won’t put all of the full details in this post—I am seriously not qualified to give advice or write a tutorial on this subject—but I will try to speed things along by providing descriptions of, and links to, the resources I used.
Here are the basic steps I followed:
Step 1. Set Up A Digital Ocean Droplet
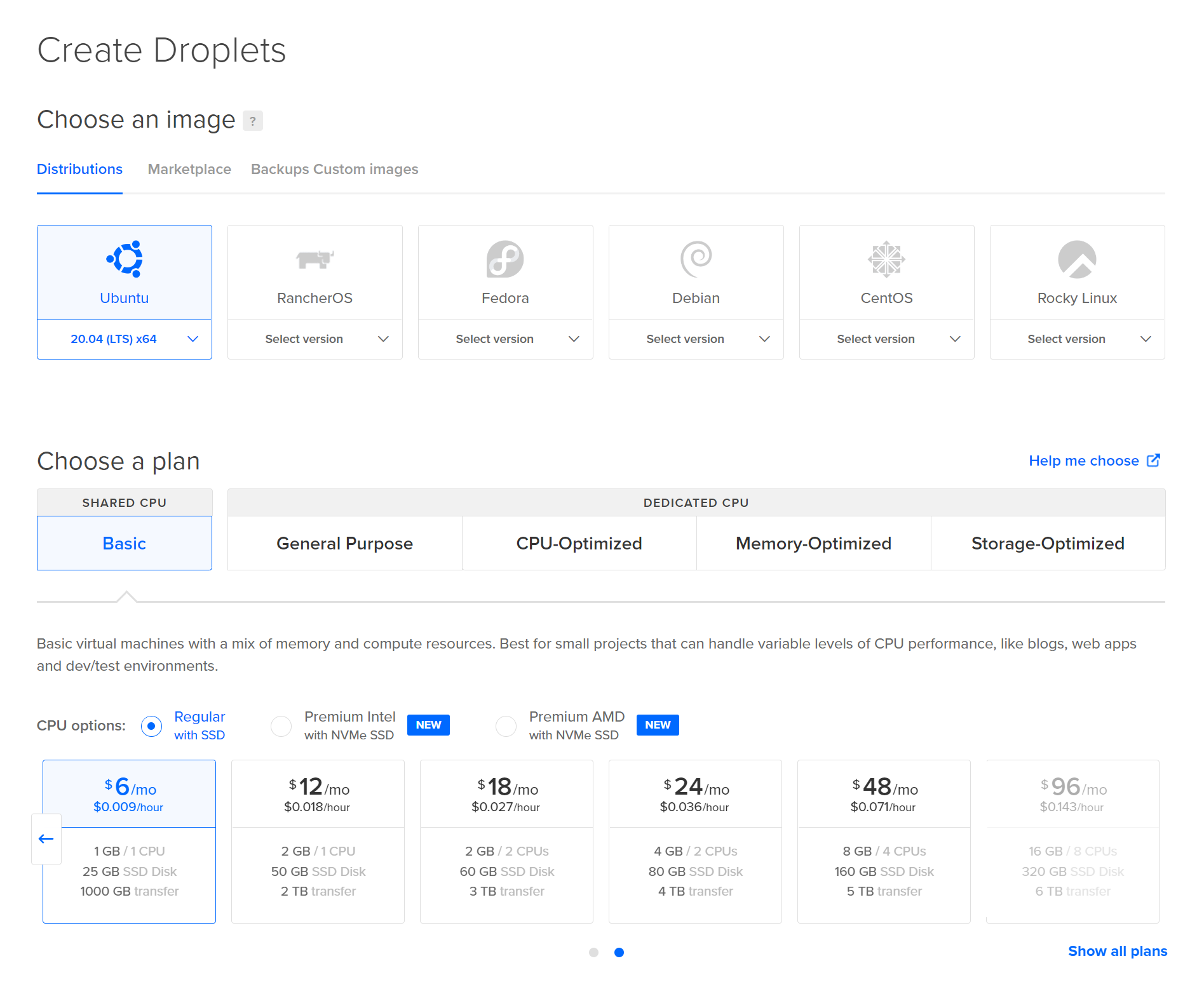
Digital Ocean is a service that allows easily spinning up a Linux server that you can SSH into. It’s fairly straightforward to go there and set up what is known as a “droplet”, which is an abstraction layer over a server. It’s an abstraction because they can easily shift it around in all kinds of spooky ways that I haven’t bothered to dig into.
The cheaper options cost something around $6 per month, which is comparable to the monthly GitHub premium price. You may want to look into other options as well—Amazon (shudder) might have some affordable options. Importantly, you aren’t glued to the server provider—at the limit, you could just set up your own physical server machine and host it yourself—but this is a fine option right now.
You’ll want to restrict network requests to your droplet to those necessary for HTTP, HTTPS, and SSH. You can do this by navigating to your droplet settings in the Digital Ocean web interface, and going to the “Settings” menu, which has a section dedicated to firewalls:

You’ll also want to enable backups for all of your data, if possible—it costs something like $1 more per month.
Step 2. Grab An SSH Client

SSH—“secure shell”—is a magic box that lets you use your server machine over the Internet. After launching your droplet, you’ll want to grab an SSH client like PuTTY, and connect to your server with it. From there, you can sign in with your password (or authentication key, if you’re fancy—and responsible), and follow the next steps.
Step 3. Set Up Gitea Instance
Gitea is a project that packages up a bunch of GitHub-like features and lets you spawn them on your own server. To do this, I ran a bunch of voodoo terminal incantations over SSH, following this guide.
Step 4. Set Up Caddy
Caddy is another magic program that makes the little lock icon show up in your browser, as seen below:

You can install it using this guide, and launch it as an always-running service on your server with this guide.
I personally set up a “Caddyfile” to configure my Caddy instance. It just specifies some parameters for Caddy so that it knows how to respond to certain requests on certain domain names from browsers. Here’s mine:
git.rfleury.com {
reverse_proxy localhost:3000
}
www.git.rfleury.com {
reverse_proxy localhost:3000
}Note: Do people still use www? I don’t know. I put it there anyways.
Gitea uses the port 3000 by default. For those unfamiliar, a “port” is another word for “magic connection secret code”.
Step 5. (Optional) Set Up Domain Name
To access your Gitea web interface from a browser with an easily-typed name (like git.rfleury.com), you’ll need to purchase a domain name (the cheaper ones being around $10 per year) and route it to your server using the DNS settings in whatever domain registrar you choose to use. That’s all of the information I’m able to provide—every time I set up DNS settings, I end up just stumbling around the web interface for my registrar and pressing buttons until it works.
Step 6. (Optional) Gitea Config Shenanigans
In its default configuration after you first launch it, Gitea will have a few settings that you may want to change—for example, the ability of anybody to immediately create an account, and the URL text that the page building code fills certain textboxes with.
If you followed the guide I linked above, your Gitea config file should be at /etc/gitea/app.ini. Inside of that file, I made the following modifications to the configuration:
[server]
...
SSH_DOMAIN = git.rfleury.com
...
ROOT_URL = https://git.rfleury.com/
...
[service]
...
DISABLE_REGISTRATION = true
...
Step 7. Double Check All Of This (Disclaimer)
I apologize for my lack of knowledge on this subject, and my facetious over-use of “magic” and “voodoo” jokes. Needless to say, I am not authoritative on this subject, so I thought it’d be most appropriate to just relay some links and the basic steps I followed instead of pretending to know what I am talking about and trying to explain it more carefully.
So, that being said, I’d recommend finding some friends who aren’t morons when it comes to setting up servers, and have them double-check what you’ve done to ensure that it is relatively secure and keeps your data safe. I had some help from some helpful folks over on the Handmade Network Discord. Your more experienced friends will be an invaluable resource when you—if you’re like me—end up getting confused at some obscure stage of the process, like setting up DNS or HTTPS.
Closing Thoughts
I find it deeply important that programmers exercise their ownership rights over their code—particularly, programmers that deeply care about fostering a community of mentorship, craftsmanship, and respect for the user. It is in my best interest—and, I’d argue, the interest of the entire computing world—that those who adhere to such an ethic find ways not only to avoid being exploited by large corporations (who act in direct opposition to craftsmanship and respect for the user), but also to find ways to be incentivized to pursue their best work.
That future will come, in my estimation, through monetization where it is due—namely, aimed at the corporation, and not at the average independent open source contributor. The engine that we can use to drive towards that future is voluntary action on the part of the owner of the code through self-hosting.
If you’re in agreement with me on this issue, I hope my guide was helpful, or at least steered you in the right direction.
If you enjoyed this post, please consider subscribing. Thanks for reading.
-Ryan
It sounds like your concerns about who uses your code, and some assurance that no entity you disapprove of sees/uses it is more important to you than making your code freely available. There's nothing wrong with that, just make it closed source.
But you can't really have your cake and eat it too. You don't get to freely and frictionlessly contribute to the greater community of developers while also gatekeeping who sees your code and what they do with it. It kinda has to be one or the other. It sounds like you picked the second, which is fine! It just means that now seeing your code isn't dependent on people being curious about it, or having good use cases, but now it's moreso about being on good terms with you.
Which again, is just fine, it's just pretty antithetical to the good aspects of open source code, and is probably going to mean considerably fewer people will ever see it or contribute to it.
software is literally just copy-pasting other people's code. how is an ai doing it any different?