
A Taxonomy Of Computation Shapes
A mental model for various forms of computation.

Many learn to program because they’re fascinated by—and talented at solving—the tricky logic puzzles involved. But those puzzles weren’t my top priority when I started programming. I can appreciate a good puzzle, but I got into programming because, originally, I wanted to build my own video games. I still loved playing video games, but I didn’t only want to immerse myself in worlds invented by others—I wanted to build my own.
Pre-built game engines existed, of course—and some of them were great at what they were trying to do. But I was frustrated by their limitations, as many of their design decisions clashed with my own plans. So, I set out to build games from first principles, so I wasn’t beholden to arbitrary designs and decisions of others.
My experience learning how to program was rewarding—but immensely frustrating. I didn’t start programming by learning how software worked from the ground up, in what many would call the “right way”. I was impatient—I started by fumbling through a dozen tutorials until I finally grasped how to draw a tile map on the screen.
There are, of course, artificial reasons why this task is unnecessarily difficult—I could write a dozen articles just about the complexity required in getting from sitting down at a computer to compiling and executing any code at all, nightmarishly complicated toolchains, and the research task inherent in finding resources worth following on day one. Half the value of having a great programming mentor is simply being told where to look, and which tools to use.
But for me, it wasn’t just the artificial problems that were difficult—it was the fundamental problems too. Humans—or at least my ancestral line—didn’t evolve to program computers. I didn’t come out of the womb reaching for a keyboard. My entire programming education was several years of bashing my head against the wall. It all barely made any sense.
Part of the problem with being a human learning to program is that everything is so opaque. Everything that you need to see to understand, you can’t. Almost all the internal codebase debugging features I write to this day—and almost all the features I’d like in a debugger—are related to visualization. I want to see the data in this way, or that way.
At the beginning of your programming journey—before you realize that all the anti-debugger propaganda you hear is nonsensical, and that you really need to find a good debugger—is fiddling around with some invisible, bitchy, fastidious program reading a text file. Then, more invisible stuff happens, and it either works or it doesn’t. It’s complete insanity. The fact that so few programmers complain about just that is a case study of mass Stockholm Syndrome if I’ve ever seen one.
It’s no wonder that nearly all the people who can program are those who like to solve tricky logic puzzles—programming itself is merely an unending sequence of tricky logic puzzles! And, somehow, an unnerving proportion of these puzzles feel like they have very little to do with the problem you set out to solve originally. At worst, many are a tedious fetch quest—at best, they’re a side quest when you want to finish the main plotline.
Every once in a while, I finish one of these side quests. I’ve written about such cases already, including user interfaces, manual memory management, building flexible data structures, and code generation. I’ve tried to package up the lessons I’ve learned from these side quests, and communicate my most useful mental models and visualizations gained from them. In doing so, I hope that these side quests might be a bit less tedious in the future for myself and others, and instead might be well-understood, concretized background knowledge. That way, maybe I—and my readers—can focus more on problems of tomorrow.
I’ve stumbled across another such lesson after doing much more multithreaded programming than I’ve done in a long time. This time, it struck me at the root, and required me to explicitly form a mental model about what computation is, how it may be organized, and its various forms.
In this post, I’ll share this mental model. It has been useful for me in thinking about multithreaded programming, but I suspect it also might be useful in visualizing and explaining computation more broadly. It may have been a useful visualization and diagramming tool for me when I first started programming.
Note that this model is descriptive, rather than prescriptive. Alone, it is not enough to provide justification for certain design decisions, and it is not a replacement for an understanding of lower level details. Someone building software still must understand how these higher level concepts map to physical reality—how they are implemented—and the various tradeoffs that occur when organizing problems in a variety of ways.
This model does not tell you how you should solve problems—it is a compressed visual language to describe and reason about systems at one level of analysis.
Shapes Of Computation
This mental model is comprised of a set of “computation shapes”. I’ll start by naming and diagramming them.
Note that these are high level concepts more akin to mathematical objects than anything physically precise, merely to aid in visualization, conceptualization, and sketching ideas out on paper.
First, here is a legend for recurring elements in the diagrams.

Now, I’ll walk through the various shapes.

Instruction. An instruction is a single unit of computation. Depending on the level of analysis, this might be a single statement in a high level language, one non-jumping CPU instruction, or one micro-operation. Computation is, ultimately, data transformation, and so an instruction may write data, and it may read data, and it may do both. For the purposes of describing this model, when I use the term “instruction”, I am not referring only to an instruction set architecture instruction.

Codepath. A codepath is a sequential list of instructions which terminates. After executing one instruction in a codepath, a computer progresses to the next. Ignore control flow concepts you’re probably familiar with—for, if, while, jmp, and so on. In this model, instructions within a codepath are not hit more than once—there is no control flow. Because there must be a finite number of instructions executed (because the codepath must terminate), consider that a codepath produced by a C function with control flow (or some assembly instructions with conditional jumps) is akin to the ordered list of instructions which actually execute, rather than data encoding instructions for a CPU.

Wide Codepath. A wide codepath is a codepath which, during its execution, causes several other codepaths which occur simultaneously. These other simultaneously-executing codepaths must terminate as well.
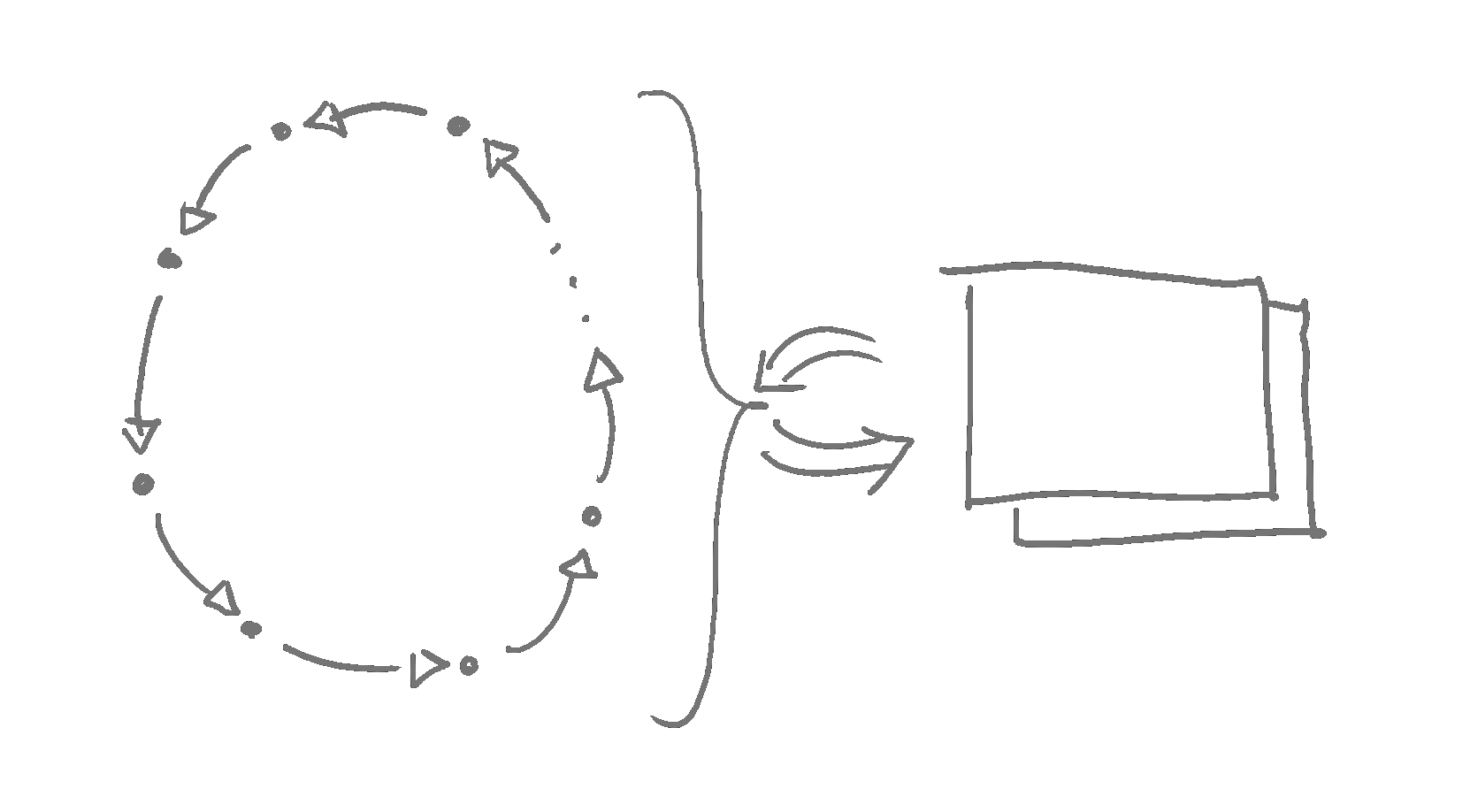
Codecycle. A codecycle is a circular structure much like a codepath, but instead of terminating, it repeats at the first instruction after the last. This is the shape used in any software which indefinitely runs. This might occur because the software must repeatedly receive and output data—for instance, code which repeatedly listens for data coming from a network, or code which repeatedly sends new data out to the network, or code which repeatedly sends and receives data from a human interacting with it.
Note that a codecycle itself may include a wide codepath, which is serially arranged with other codepaths. This becomes useful when one task is serially depended upon, but may be completed in non-serially-dependent subdivisions. A great example of this is rendering a frame—one pixel color produced by a render pass is entirely independent from another. So, there are major performance advantages in producing colors for multiple pixels simultaneously.

Wide codecycle. A wide codecycle is akin to a codecycle just as a wide codepath is akin to a codepath. It is multiple codecycles, but all participating in performing the same computational task simultaneously.

Codecycle Graph. A codecycle graph contains multiple codecycles, and the data from which they read and to which they write. Data can be shared, meaning it may be written to and read from by multiple codecycles.
Usage Of The Shapes
As I mentioned before, these concepts are useful for description, not prescription. One’s problem many solutions may manifest in many forms in this model—choosing between these forms requires deeper understanding and more details than this model provides.
I’ll now provide a slightly more real example of this model being used, to both demonstrate what it describes, but also to be clear about what it does not describe.
The following example uses these concepts together, and outlines the high-level structure of a program which asynchronously performs: (a) user interface building and interaction, (b) loading file disk contents into memory, and (c) analyzing (presumably parsing or extracting data from) the contents of those files. Each of these tasks—(a), (b), and (c)—have associated codecycle(s).

First, it’s interesting to consider the reason why this design might separate these three tasks into multiple codecycles, instead of merely performing all of them serially within a single codecycle. The user interface task operates on a deadline—it ideally receives input from the user, and pushes out frames to the display at 60, 120, 144, or 240 Hz. Heavier tasks, like accessing large storage from disk, or doing analysis on it, may (and often do) violate that deadline. If the user interface codecycle halts, then communication with the user also halts. If the user needs information about file I/O, or file analysis, or if they simply could be productively using the program in other way while those tasks are occurring, then it’s unacceptable to perform these tasks serially.
Separating these tasks, of course, requires considering the serial dependence of various tasks. It’s clear, in this case, that while—for instance—file analysis might be serially dependent on file input, building a useful user interface and receiving input from the user is not serially dependent on either of those tasks. Similarly, loading a second file is not serially dependent on analysis of the first (assuming that the second file is known before analyzing the first).
In other words, these three tasks can repeatedly occur on different timelines. They can overlap with each other.
In a practical scenario, it’s important to consider the details—if loading file data from disk and performing analysis is relatively quick, and occurs once at startup, or if it is small enough to be trivial repeatedly, then there is not much benefit gained by separating these tasks like this.
This model also visualizes where synchronization might need to occur (between various codecycles—implemented with threads), and thus where contention may occur. If data is not accessed by multiple codecycles, it does not require synchronization. Special cases of shared data may be less of a contention problem than others—for example, a directed queue, into which “producer” codecycles write, and from which “consumer” codecycles read.
Closing Thoughts
To conclude, I want to reiterate that this has been a useful language for describing concepts, but still requires thought about the realities of one’s problem. When I use this model, I think of it as sketching out a schematic for a machine. Having well-established patterns for schematic drawing is useful—but it’s important to remember that no matter what the schematic looks like, it may not work in practice.
I hope this post provided a useful mental model, or if nothing else, provoked some interesting thinking.
If you enjoyed this post, please consider subscribing. Thanks for reading.
-Ryan