
Factorio, Mutation, & Lossiness
On Factorio, the high-level term "data transforms", how data transforms are practically implemented, and tradeoffs to consider in various implementation styles.

I heard about Factorio not long after its 2016 release. Within the span of a few months, several friends of mine developed a new addiction—it wasn’t to any kind of physical substance, but it might as well have been. As such, I avoided playing it at first; I wanted to give it a try when I knew I had a few weeks of time off, and such periods become exceedingly rare when side projects and hobbies are in the mix.
It wasn’t until later that I learned: Factorio was different from any usual open-ended game. A friend of mine explained that the game had changed the way he thought about programming. But Factorio isn’t quite a “game about programming”—or at least it doesn’t present itself as such—like the Zachtronics titles TIS-100 and EXAPUNKS, in which the player does, in effect, real programming in simplified virtual environments. But some of the game design fundamentals in Factorio were, somehow, intrinsically connected to programming fundamentals, and understanding the link had opened some kind of mental door.
Hearing this, I was intrigued. But it wasn’t until a few weeks ago that I finally spent my first ~20 hours on Factorio (within the span of a few days), and began to understand firsthand.
There is probably enough material on the topic of Factorio and its relationship with programming to span several posts, not just one, and I’ve not even exhaustively played through the game. Its mechanics connect with the computation shapes I’ve written about before. Asynchronously-running factories can be starved, and have throughput problems (either in consumption or in production). As such, it has lessons I’d say are relevant for programming asynchronous systems. But in this post, I wanted to focus on one idea that playing the game made extremely clear—and it has to do with the often-used term “data transform”, and what exactly that means.
In 2014, Mike Acton reminded confused programmers about the simple truth that computer programs are not about abstract models; they are about commanding physical machines to perform computation, and the best abstract mental models to describe that architecture do not obfuscate that underlying concrete reality, but rather emerge from it. The mental model Acton presented was that traditionally used by programmers: the “data transform”—all computer operation can be understood as taking some data as input, and producing some other data as output.

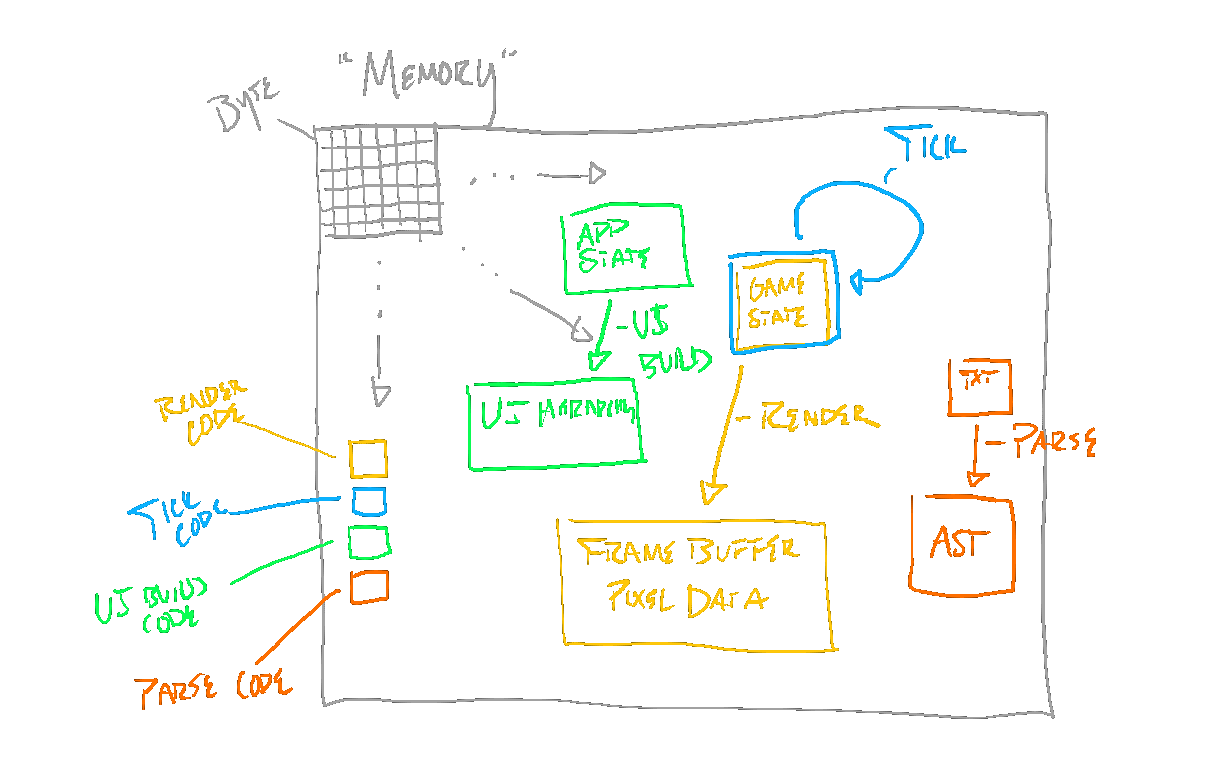
And what are A and B? They are encoded as data—meaning some values written into memory—on a computer, and the transform is a cohesive path of computation using some code (simply other data encoding instructions). In performing the computation, the computer reads from A, and writes to B. This pattern can be used to describe the effect of any codepath:

When a game “renders”, it’s applying a transform which takes its level state as input, and produces a framebuffer as output. When a game “ticks”, it’s applying a transform which takes game state at some start time, and produces game state at some end time. When a program “builds a user interface”, it is applying a transform which takes the application state as input, and produces a user interface hierarchy data structure as output. And when a program “parses text”, it is applying a transform which takes textual data as input, and produces an abstract syntax tree as output.
The fundamental reason why Factorio connects to this model is that the game’s mechanics are also a system for expressing data transforms. In Factorio, A and B manifest as items used in a variety of recipes. For instance, A might be iron ore and coal, and B might be smelted iron plates.

In Factorio, the “computers” performing the transforms are the furnaces and assembly machines, which are capable of automatically smelting ore, and crafting items. The conveyor belts transport “data” from one computational path to another. This allows multiple computational paths to compose, and form more sophisticated computational paths.
But notice that the model of data transforms—A producing B through computation—is still an abstract model, and it may manifest physically in a variety of ways. Imagine, now, how data for A and B are stored physically, by arranging them spatially:
Two distinct patterns emerge—one where A and B are not stored in the same place, and one where A and B are stored in the same place. If A is defined as being that which is read by some codepath, and B is defined as being that which is written by some codepath, then in the first pattern, A can be defined as being considered immutable by the codepath. In the second pattern, A can be defined as being treated statefully by the codepath.
During my time playing Factorio for the first time, I ran into a number of architectural mistakes in my factory. I set up rows of furnaces which took iron ore and coal as inputs, and produced iron plates as outputs. I also realized I needed to smelt copper, so I set up another row of furnaces which took copper ore and coal as inputs, and produced copper plates as outputs.
After I had built these two “computational paths”, I had assumed I had moved on from coal and raw ore, to bigger and better things. I had obtained the smelted plates, and that is surely all that would be important later on—the furnaces, the raw ore, and the coal was simply an intermediate step.
The plot of Factorio begins with the player crash landing their ship on an alien planet, occupied by various giant insect-like species. The game begins somewhat peacefully, but as the player begins making noise, polluting the environment, and so on, the alien insect-like species become unhappy, and they begin to attack. There are a number of options, at this point—the player can pursue a more peaceful path, setting up basic defenses, but moving quickly to coexist with the insects, or the player can pursue a more militaristic and aggressive path, in which the player invests heavily in military and weapons research, such that they’re able to eliminate any alien species hoping to stifle their plans.
I probably don’t even need to say this—readers of mine surely know my temperament well enough to predict it—but I, naturally, went with the latter path. I was on a mission—alien planet and aggressive insect species be damned.
So, in pursuing my militaristic strategy, I needed to begin mass-producing grenades—because of course I did. There’s just one problem, though—the ingredients required for producing those grenades? Well, they included coal.
This was far beyond the initial architecture phase of my factory—I had built everything assuming I’d not need coal past the initial stages of production. I used it for some transform earlier, and I thought that was all there was to it. I had lost the presence of coal in my factory, in the location where I needed it.
So, I needed to rearchitect some things—I needed to use the coal to produce smelted iron and copper plates, but I also needed it for other things (my grenades), so I needed to continue piping it through the factory.
After hitting this and other similar mistakes, I adopted a simple and effective approach for my factory—lose no ingredient. Pipe every intermediate artifact through the factory—make every ingredient available at all times, such that if I found a new recipe, I’d either have all the ingredients trivially available, or I’d have some ingredients I didn’t have yet, and that I needed to go and produce first.
The following shape emerged:

The factory runs from top to bottom. It begins with only a single ingredient—coal. As it progresses downward, it widens, incorporating new ingredients from mines, furnaces, or assembling machines. If I need to automate a new recipe, I simply redirect the needed ingredients off to the side, where I produce the new ingredient, which gets rerouted as another conveyor belt.
Another important characteristic of this solution is that it deduplicates the production of various intermediate ingredients. Iron plates are used to produce gears, which are used in a number of recipes—I didn’t immediately assume I needed a main-line conveyor belt of gears, so I needed to duplicate gear production in multiple places. This has complicated effects on starvation and throughput in various parts of the factory—but rearchitecting this such that there is only one place producing gears centralizes these effects, making them much more easily diagnosable, and much more easily addressed.
This design also answers a number of questions. With this design, discovering whether or not I can produce some new recipe easily is not a complex, open-ended question— “Well I produced that required ingredient in that other part of the factory, can I somehow reroute it over to this location? How much space will that take? Will I need to shift some things around?”—but a simple, trivially-answered question: Do I have the ingredients, or do I not? If not, those must be produced first—the process repeats.
The mistake which led to this design is what I wanted to focus on in this post, because it is an identical mistake to one I used to regularly make while programming, and one I see programmers regularly make today. It connects with what I wrote about earlier—treating a codepath’s input as immutable, or treating it as stateful.
Fundamentally, the problem I ran into with my original factory architecture was one of lossiness. Considering each ingredient as unique “information” at each step along the vertical top-to-bottom path of the factory, I had the “information” of coal at some point, early in the factory’s architecture. When I assumed I’d never need coal again, I threw that information away, and replaced it with the information of iron plates.
This exact same pattern occurs with stateful code. Every time code writes to data which it read, it loses the original information it could obtain by reading that data.
Now, importantly, this is sometimes simply the nature of implementing machines which deal with stateful concepts—it isn’t a problem that can be avoided in all cases. Sometimes, a state machine is simply a state machine, and old states are naturally lost. Sometimes, keeping old states around is prohibitively expensive. Sometimes, the old states are never again useful, so even if it isn’t prohibitively expensive to keep those states around, doing so has no net benefit.
But sometimes, not immediately throwing away intermediate computational artifacts can prevent headaches.

I mentioned this in a recent video, while walking through the Digital Grove codebase, explaining this part of my programming style, and why and how it shows up in the codebase.
The main advantage in retaining intermediate computational artifacts is that, in many cases, the right “ingredient” for a codepath is not the result most recently obtained by some computation. In many cases, some computation needs to reach back in time, and use some data from several steps back. Notice in the above diagram—in the screenshot from the video—that the fourth step in the sequence of computational steps is possible on the left, but not possible on the right, because of this “lossiness”.
Another advantage is in one’s predictive ability over how code may execute. When some artifact is produced and enters a scope within a codepath, it will not suddenly change in a way that’s invisible to a reader of the code. When mutation does occur in such codepaths, it can be locally confined, such that it’s obvious in context.
A third advantage is in debuggability. Because the history of some chain of computations is not lost when those artifacts are not thrown away, stopping a thread at the end of that chain of computations—by setting a breakpoint in a debugger, for example—allows one to trivially examine what a codepath produced at each step, without needing to go and step back through the codepath as it was originally encountered.
These advantages have led me to generally prefer retaining intermediate artifacts from significantly complex codepaths, rather than losing them, when it’s feasible (which it often is). It is often not needed nor feasible, but this general preference (when in the realm of utility and feasibility) has helped me avoid many headaches, and stay organized in thinking through, and then producing, the computational effects I want.
As with all rules-of-thumb, though, it’s always a judgment call. This preference simply does not apply in all places. It’s useful, for example, to retain artifacts like the tokenization of a textual buffer, as well as the parsed abstract syntax tree of those tokens. It’s never useful, on the other hand, to implement a for-loop as a recursive function, to avoid mutating a counter variable. Sometimes mutable data is simply the correct choice for a problem.
But one can only make said judgment calls appropriately if they understand the breadth of options, and the tradeoffs of each. Thinking about computational artifacts as information, and understanding that they are lost when mutated, was an important lesson for me to learn in understanding my options when tackling new problems, so I decided to share it here. I hope it’s useful information for you too.
If you enjoyed this post, please consider subscribing. Thanks for reading.
-Ryan
Looks like you eventually made a BUS on central path! Well done! How far did you get?