
The Easiest Way To Handle Errors Is To Not Have Them
On structuring code in an "error-free" way.

Programmers are taught early to spend a great deal of time considering “errors”, and how to “handle” them. But one of the most important programming lessons I’ve learned over the past several years is to dismiss the idea that errors are special. At the bottom, the computer is a computer. It’s a data transformation machine. An error case is simply a case. Data encoding an error is simply another form of data. Irrespective of how many language features and type variants one decides to layer on top of the computer, nothing changes this fact.
In the usual educational programming journey today, this underlying reality is ignored if not quickly dismissed, and the programmer is taught to consider errors as higher level, abstract concepts, which are distinct from non-errors. But regardless of the time spent learning to “handle errors” in this way, actually handling errors never seems to become completely painless—in the best (for the programmer’s comfort—but perhaps worse for the software) case, the programmer is taught to remain blissfully unaware of the holes in their “error handling” strategies, and the consequences of that are, well, all around the modern software world, in overly-rigid or legalistic designs, unexplained failures, invisible rules which dictate successful or unsuccessful software usage, and so on.
One of the important design problems in any computing system is in robustness to a variety of conditions—including error conditions. Computers, at the bottom, are precise physical machines. If one hopes for them to interact seamlessly with other computers, or with humans, then they must fluidly adapt to error conditions, and provide pathways to gracefully recover and continue operating, such that a human could learn, adapt, and try again.
At some levels of abstraction, the concept of an “error” does arise—but as I’ve discussed before, it’s much more productive (both for the programmer and the computer) to consider the higher level manifestation of an idea as emerging from some underlying computational machinery, rather than architecting computational machinery according to some abstract idea. Things which are concretely identical ought to be organized as such. Systems which respect concrete reality will perform better, and result in fewer headaches, than those which don’t.
Once error cases are understood to be no different from normal cases, they may be understood with normal analysis. In past posts, I’ve written about codepaths—one possible trace of execution on a computer—and how code can be architected such that it produces a large combinatoric explosion of codepaths, or—preferably—such that it collapses all desired effects into as few codepaths as possible. Fewer codepaths means those codepaths receive more programming time, they’re exercised more regularly, and tuning those codepaths (for performance, for instance) will have a much larger impact.
In other words, because every new codepath represents a new possibility of code execution, it also represents a new possibility of code failure, and thus an opportunity for testing and further development work.
Error cases being simply cases is another way of saying they correspond to a subset of all possible codepaths. If error cases can gracefully flow through the same effective codepaths through which other cases flow, then handling those errors becomes nearly free. As such, the handling of those errors can come at a remarkably low cost, instead of being an annoying extra constraint which must be “handled” by the “real” code.
It’s all real code, because they’re all real cases.
In this post, I’ve gathered a set of principles and techniques which have helped me use this reality to my advantage, and helped me write much more robust and failure-resistant code, which more gracefully adapts to changing conditions.
Guarantee Valid Reads (Nil Pointers)
One way code may fail is reading or writing to a virtual address to which it doesn’t have access, causing an access violation. This might be by reading or writing to a null pointer. Because of this, code is often written in an extremely paranoid fashion, littered with ifs or asserts, in an attempt to catch invalid pointers (and ideally deduce how they arose), hopefully before software runs on a user’s machine:
Foo *foo = malloc(sizeof(Foo));
assert(foo != 0);
InitializeFoo(foo);
Bar *bar = foo->bar;
if(bar)
{
// use `bar`
}In simple cases this is not a major concern, but the complexity compounds for each pointer which, when read or written to, would cause an access violation. Each if, assert, or early return is representative of a multiplying by 2 of the number of possible codepaths. This leads to situations like those I’ve described in past writing, where the programmer must explicitly add code per codepath. When the set of codepaths grows exponentially with each new possible failure point, this results in slow, long, noisy, and difficult-to-predict code.
Now, some of these possible codepaths correspond to genuine failure cases. If code attempts to allocate a buffer to which it then writes, but the allocation fails, there is not really much that the rest of the code can validly do. I’ll speak more on that case later. But first, I’d like to focus on the case in which a pointer is only being read from.
The primary reason reading from pointers (prepared by other codepaths) may cause an access violation is because code preparing the pointers often makes the decision to (a) return a pointer to some valid and accessible spot, or (b) return a null pointer. In the case of (a), the pointer can be read from without an access violation. In the case of (b), it cannot.
But a simple solution is to prefer option (c) to (b)—return a pointer to a “nil struct”, rather than a null pointer, if (a) fails. This nil struct is allocated up-front and may be stored in read-only memory. Any pointers contained in the nil struct point to other nil structs of the associated type. If there are pointers to the same type, they point at the same nil struct in which they’re contained (in other words, the pointers are self-referential).
struct Node
{
Node *first;
Node *last;
Node *next;
Node *prev;
Node *parent;
Payload v;
};
read_only Node nil_node = {&nil_node, &nil_node, &nil_node, &nil_node, &nil_node};Note: read_only, a macro I define in the Digital Grove codebase, can be easily implemented as expanding to compiler-specific allocation attributes—e.g. on MSVC, __declspec(allocate(".roglob")), where .roglob is a section earlier defined with #pragma section(".roglob", read)
If this pattern is adopted, then irrespective of failure or success of the codepath preparing a pointer for later use, it is guaranteed in all cases—given completion of the codepath—that the resultant pointer is readable.
This collapses all cases in which later code required two codepaths—one for a valid pointer, one for a null pointer—down into only requiring a single codepath. This simplifies the multiplicative effect that each pointer brought, down to a multiplication of one.
In other words, this (an example from a previous post):
Node *SearchTreeForInterestingChain(Node *root)
{
// assuming `ChildFromValue` derefs its parameter.
// obviously these `if`s can be hidden inside the
// API too, but that doesn't change the fact that
// they happen, nor remove the burden from *someone*
// to check...
Node *result = 0;
if(root)
{
Node *n1 = ChildFromValue(root, 1);
if(n1)
{
Node *n2 = ChildFromValue(n1, 2);
if(n2)
{
Node *n3 = ChildFromValue(n2, 3);
if(n3)
{
result = ChildFromValue(n3, 4);
}
}
}
}
return result;
}…turns into…
Node *SearchTreeForInterestingChain(Node *root)
{
Node *n1 = ChildFromValue(root, 1);
Node *n2 = ChildFromValue(n1, 2);
Node *n3 = ChildFromValue(n2, 3);
Node *n4 = ChildFromValue(n3, 4);
// we will necessarily get here - and we're also
// guaranteeing for all of *our* callers that they
// can dereference this result, even if it's 'invalid'
return n4;
}In my experience this dramatically simplifies a lot of code, which never needed the “validity” check, but could gracefully work with the “empty” values of a nil struct.
This technique is further helped if the nil struct contains useful default values, and ensuring this is especially simple (and performant) when zero is a useful default value in all cases.
Make Zero Values Valid (Zero-Is-Initialization)
Many modern programming styles are obsessed with default values and initialization, as a property of type information. C++ added “constructors” to what otherwise would be plain-old-data structs, which are arbitrary functions that implicit run when the language can statically recognize that a type is being instantiated (e.g. via stack allocation or the new operator). The entire concept of RAII (Resource Acquisition Is Initialization)—one of the goals of C++’s constructors—is that the presence of some type instantiation offers the guarantee that the instance is initialized.
But the best—simplest, fastest, and most maintainable—code is that which never needed to be written, or to be executed (as its intended effects are already gracefully accomplished through other means). In the case of initialization, this is trivially attainable if all initialization can be simplified to zero initialization.
If zero initialization is sufficient for memory initialization, several benefits follow. First, freshly committed memory returned by modern operating system allocation APIs (e.g. via VirtualAlloc) is always already zeroed entirely, and so in that case, no additional work must happen. Second, the code for zero-initializing memory (if unable to rely on default zero-allocation of freshly allocated pages—e.g. if reallocating an already-previously-allocated chunk) is trivial, being a single memset. It’s completely generic and independent of what the underlying type is, which members it has, its size, and so on. Ultimately, zero initialization is trivial to write, trivial to execute, and trivial to maintain.
Within the context of error condition robustness, these benefits go further. When this pattern is adopted codebase-wide such that most data is zero-initialized, and also that most codepaths accept zero values, any data which fails to be constructed (due to what might be considered an “error”) will remain zero-initialized, and thus will gracefully work with the codepaths that later consume it. This applies to nil struct pointers—which, with the exception of pointers to other nil structs, are completely zero-initialized—but also other cases, like a struct allocated on an arena or the stack, returned from some API.
Zero initialization is subtle because it—despite its title—describes only a small part of “initialization” code—after all, almost all initialization code disappears. It instead mainly describes a general property of all non-initialization code—the fact that any codepath which reads from some input, could have that input made zero, and it’d behave as expected, with as-sensible-behavior-as-possible (for whatever the context is).
A trivial example of this is the String8 type, and related string processing code, in the Digital Grove codebase:
struct String8
{
U8 *str;
U64 size;
};This is the “string view”, or “slice” type, used for all codepaths which read from strings. If an instance of String8 is zero-initialized, all code into which that instance is fed will interpret the instance as encoding an empty string—the code will gracefully allow str to be 0, as all operations are delimited by size (also, in this context, obviously zero).
Another, slightly more complex example is found in the Metadesk text format parser in the Digital Grove codebase. This layer contains a lexing API (which takes care of all tokenization work before the primary tree parsing pass):
struct MD_TokenArray
{
MD_Token *v;
U64 count;
};
struct MD_MsgList
{
MD_Msg *first;
MD_Msg *last;
U64 count;
MD_MsgKind worst_message_kind;
};
struct MD_TokenizeResult
{
MD_TokenArray tokens;
MD_MsgList msgs;
};
MD_TokenizeResult MD_TokenizeFromText(Arena *arena, String8 text);The types which are returned from MD_TokenizeFromText—MD_TokenArray and MD_MsgList—are both initialized to zero. Both are processed by code which looks like the following:
MD_TokenizeResult tokenize = MD_TokenizeFromText(arena, text);
for(MD_Msg *msg = tokenize.msgs.first; msg != 0; msg = msg->next)
{
// print out `msg` info
}
for(U64 token_idx = 0; token_idx < tokenize.tokens.count; token_idx += 1)
{
// use `tokenize.tokens.v[token_idx]`
}Similar to String8, this code gracefully works with zero initialization, as both for-loops above are delimited by either a null first pointer in the MD_MsgList, or by a zero count in the MD_TokenArray. So a zero initialized String8, MD_TokenArray, MD_MsgList instances are all naturally consumed as “empty”.
One of the major exceptions to zero initialization as a rule is that it’s sometimes worthwhile to compromise it for the purpose of providing nil struct pointers. But whether or not this is worthwhile depends on the case. In the above case—the MD_MsgList pointers—I don’t use nil struct pointers, because the list is processed as a batch, and as such is naturally terminated by null pointers. If I wanted the ability for code to—for example—gracefully read the first node and read the first value—or a nil struct if no such value existed—then nil struct pointers might be worthwhile. But for simple list types like this, my feeling is that the tradeoff weighs more strongly in the “don’t add more global nil structs, keep loops terminating at 0” direction, since it’d be unlikely that the list isn’t processed entirely at once.
One way in which both zero initialization and nil struct pointers can work together without conflict is when pointers are not stored in any stateful, mutable data structures, but only constructed on-the-fly (in an immediate-mode fashion) from—for instance—indices or handles stored in mutable data structures. In that case, zero indices or handles can be treated as mapping to a nil struct pointer, such that when user code does eventually resolve those indices or handles to pointers, it’ll resolve zeroes to nil struct pointers.
If You’re Going To Fail, Fail Early
I’ll now return to the “allocate buffer, write into the buffer” case. I already covered what might happen when a pointer is being read from—an API implementation can guarantee for its users that pointer reads (with some caveats—e.g. delimited by a size) are always valid. But nil structs are allocated in pages marked as read-only, and for good reason—if they weren’t, code which received a nil struct pointer and wrote to it could compromise other code which expected reads from nil structs to contain useful and empty defaults.
So, receiving a nil struct pointer and writing to it is a bug. What approach should one take, then, when using pointers for the purpose of writing?
To dig into this problem, consider the following code:
U64 *buffer = ...;
buffer[0] = 123; // ???On the second line, is accessing buffer[0] “unsafe”?
The answer, of course, depends on what the “...” is replaced with. Contrary to popular belief, using a normal pointer isn’t a game of Russian Roulette for a program—it all depends on what guarantees have been made at this point in the code. Also contrary to popular belief, special language features do not magically make this problem go away, because depending on said guarantees, there may be a genuinely possible failure point, or there may not be.
But consider that “...” is replaced by malloc(64*1024*1024*1024):
U64 *buffer = malloc(64*1024*1024*1024);
buffer[0] = 123; // ???There is no way around the fact that this represents a genuinely possible failure case—the software was produced with the expectation that the user’s machine would allow a 64 gigabyte buffer to be malloc’d. The software is running on a real machine, with real, fixed resources, and is using an implementation of malloc which was built with various constraints. Such an allocation may not succeed, depending on many factors.
Let’s also suppose that this 64 gigabyte buffer is completely necessary for the problem. This means that the programmer has no choice with respect to whether or not he allocates the buffer—he knows he needs it. But he does have a choice with when the buffer is allocated, and what to do if the allocation fails.
Furthermore, the user cares when the allocation happens, if the allocation fails. The user also cares about not losing progress, or state. For the user, if the allocation is going to fail, the earlier the better. This is for a fundamental design reason—human computer interaction is cyclic. The user supplies input to a compute system, the compute system produces output, which is then interpreted by a user, which the user anticipates before feeding more input into the compute system.

If the relevant output of some system is that “the operation cannot possibly succeed”, forcing the user to jump through several hoops, prepare state, and then telling them the operation cannot succeed is wasteful of the user’s time—and a hell of a lot more frustrating—than simply telling them up-front, immediately after the user triggers the operation.
Communicating such information to the user as early as possible is paramount—the software must not arbitrarily prolong the length of the “compute system cycle”.
A good rule-of-thumb I’ve found is that these potential failure points should occur in as shallow frames in the program’s call stack as possible, and I ought to exert pressure to eliminate many of these potential failure points—having them around is not free.
Take the following call stack:
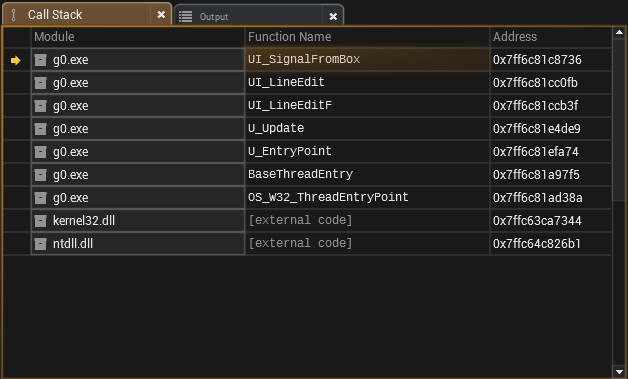
If I force these failure points to occur, say, within U_EntryPoint, rather than UI_SignalFromBox, I force more pre-allocation. Before the software gets into the weeds of its operations, it guarantees it can successfully perform those operations, and that it has the required resources. This way, I guarantee more sooner, and learn more about failure points earlier. This allows me to inform the user much earlier, which keeps the compute system cycle short.
Arena allocators are a beautiful example of abiding by this rule-of-thumb without sacrificing the potentiality and upsides of dynamism. Arenas have the ability for dynamic growth—and each dynamic growth represents a possible failure point—but the shape of their allocation interface is catered to lightning fast allocations off a pre-allocated block of memory. So during development, or in shipping builds where dynamism is preferred over static requirements (or required), arenas can implement common case allocations with lightning fast allocations off a pre-allocated block of memory, but fall back to dynamic growth paths. But when tightening up code such that it’s nearly bulletproof, the same arena can be adjusted to work completely off of a fixed up-front reservation size in all expected cases—and the decision about the static requirements of this fixed up-front reservation can be made later, when there’s enough information to responsibly make it.
In any case, after the guarantee has been made that this sort of buffer allocation has succeeded, accessing the buffer (assuming the access is in-bounds) is guaranteed to be valid. All code subsequent the guarantee may take advantage of this fact—ultimately, this means that there are no pointers to check, no asserts to write, no paranoia—the pointer is valid, guaranteed. All codepaths which access the buffer need not be bifurcated for the possibility of failure—they’re already by definition within the success path, so no further combinatoric explosion of codepaths occurs.
Prefer Fewer Types—Or, Prefer AND over OR
Another facet of modern programming techniques and tooling is the addiction to the generation of new types. Many programmers have come under the spell of deeply desiring the structure of the program itself to be encoded, somehow, within a language’s type system, with some vague expectation that the code—after all the types are established—will practically write itself. This addiction is also facilitated by a programmer’s fixation on perfectly compressing all instances of all types—all data must be encoded in types in which all parts of that type are likely used, and wasted space is not acceptable.
I think this perspective misses a crucial detail of the relationship between types and code. The fact of the matter is, the larger the number of types, the larger the number of required codepaths. It’s not obvious how exactly these numbers are related, but the general correlation is clear—types define the texture which two codepaths must agree on in order to “click together”. Introducing more types necessarily requires more codepaths in order to “click into” those textures.
One way in which the addiction to generating types surfaces in the context of “error handling” is the presumption that the resultant type of some codepath is either a successful value produced by the codepath, or it’s an error. Ultimately, the instinct in this style of programming is to build a sum type which may encode valid results or invalid results. And as I’ve previously covered, a source of combinatoric codepath generation is in the overuse of sum types—in short, because they introduce questions about an instance of a type’s data format, rather than answers.
A helpful lesson for me was in reframing error information returned by a codepath as error information in addition to whatever the “non-error result” is. This small change eliminates needless bifurcation of the code receiving the result—it can simply be one codepath which processes both valid results (or gracefully no-ops, if the valid results are zero-initialized), and any error information.
The Metadesk lexer API from the Digital Grove codebase is a simple example:
MD_TokenizeResult tokenize = MD_TokenizeFromText(arena, text);
for(MD_Msg *msg = tokenize.msgs.first; msg != 0; msg = msg->next)
{
// print out `msg` info
}
for(U64 token_idx = 0; token_idx < tokenize.tokens.count; token_idx += 1)
{
// use `tokenize.tokens.v[token_idx]`
}The parser API follows the same pattern:
struct MD_ParseResult
{
MD_Node *root;
MD_MsgList msgs;
};
MD_ParseResult MD_ParseFromTextTokens(Arena *arena, String8 filename, String8 text, MD_TokenArray tokens);This makes especially good sense because it allows the returned MD_MsgList to refer to MD_Nodes and MD_Tokens—both types, together, are more powerful than either in isolation.
In my experience, this API style allows usage code to, more-or-less, ignore the distinct idea of “errors” altogether, until it actually cares to use error information (e.g. to display error information to the user). Most usage code can simply be a single effective codepath—or in other words, it can have a completely flat control flow structure, which simply performs the required data transformation steps, in order.
Writing this, I can’t help but feel that it’s a fairly trivial lesson—but for those feeling similarly, it’s good to remind oneself just how overcomplicated programmers like to make their problems, and just how much they like to present the façade of productivity by playing around with type systems. I don’t care to digress into modern language feature design around errors—it’s trivial to find online—but in my view, the fact that there is such a widescale (and often passionate) conversation about the “need” for “error handling language features” is indicative enough of the embarrassing state of software development.
Error Information Side-Channels
errno is a globally-available, thread-local integer in the C standard runtime library, which is mutated by APIs implicitly when an error condition occurs.
Aside from a number of silly implementation details of errno, there are reasonable aspects of its design. Notably, it follows other principles outlined in this post—it doesn’t needlessly harp on the validity of results, resulting in needlessly-bifurcated usage code codepaths. It follows the principle that error information ought to be available in addition to, rather than instead of, “valid data”. Instead, it’s used to implicitly collect error information, and it allows usage code to perform whatever operations it needed, and only check when needed.
One serious problem with errno is that it’s a single thread-local slot for error information, so it’s only enough to inform usage code of the most recent error. Another is that there’s no way of knowing which code set errno last, and when.
These are fairly serious limitations. The lack of capacity and the lack of error source location information prohibits errno from being meaningfully used in more shallow frames in a call stack, which would otherwise be an extremely powerful usage pattern.
Consider, for example, if I wanted to—at the end of each simulation loop, in a game project—process all implicitly-gathered error information, and maybe render them in a debug user interface (maybe as a timeline, or flame graph). Every point in this timeline would represent a place at which error information was gathered—it could include call stack with function names, source code location, and so on. It could be integrated with a debugger such that breakpoints could be easily set when one particular error (in a particular call stack) occurs.
This is all easily doable with more powerful “side-channels” of error information, which don’t have the critical shortcomings of errno.
And contrary to yet another popular belief, programming is not delimited by decisions made while designing the C runtime library. All languages—including C—can take on entirely new forms when someone is willing to go to work and design an alternative “standard” library and environment (which is part of my goal through the Digital Grove codebase). Memory management, string processing, error handling, run-time type information, compile-time execution, metaprogramming, and a great many other things can become dramatically simpler than they’re often portrayed by those who spend more time arguing about languages on HackerNews or Reddit than they do programming.
Instead of each thread being equipped with a single integer, it can be equipped with an entire arena and message log:
per_thread Arena *log_arena;
per_thread MsgList log_msgs;Each message stored in the MsgList can be equipped not only with a single integer, but with a callstack, a string, a color, and whatever other information is deemed useful.
This kind of design avoids the extreme lossiness of e.g. errno, but keeps code humming along smoothly. Within this context, “error handling” is simply the ability for code to gracefully continue operating in the presence of errors, with the error information accumulated in a log to be later inspected.
Logs of this kind allow not only for powerful introspection of a trace of codepath execution, but using them as a primary mechanism for error data gathering keeps each codepath honest about operating soundly and gracefully in the presence of errors. Like many of the lessons in this post, this keeps the number of codepaths small, and thus the value of programmer work high.
Closing Thoughts
The tendency for programmers to build towers of abstractions over bad fundamentals has several fundamental issues. Better designs—which do not compromise on the fundamentals—are obfuscated. Programmers detach from fundamental reality. They teach others to detach from fundamental reality, such that future improvements are much more difficult to design and conceptualize. Programmers settle for subpar compromises on the performance and simplicity of an abstraction (which, in a pragmatic context, may be completely reasonable—but poor abstractions substituted for good ones, used for pragmatic reasons, are obviously not the endpoint of abstraction design in any area). Arenas are an example of one such better design—they do not compromise on the low level details, and they simplify higher level work. They’re a clearly superior alternative to gigantic complex memory management systems, and one that could only be identified when considering the problem near the fundamentals.
“Error handling” is much the same way. By dispensing with abstract notions of “errors”, and treating the computer as a computer, and data as data, and code as code, the fundamental reality of errors can be grappled with, and grappling with that reality bottom-up can lead to much simpler problems than when theorizing about the same problem top-down. Errors, by-and-large, disappear.
I’ve found that, with this mindset, my software became much more robust, my code became much simpler, and I rely on much simpler tools. I didn’t need another language feature; I didn’t need another library; I just needed to take control of my problems.
I hope this post helped communicate to you these same lessons, which I’ve benefitted so much from.
If you enjoyed this post, please consider subscribing. Thanks for reading.
-Ryan
Great article packed with good information as always.
This is similar to the "null object pattern" in OOP, albeit lacking polymorphism. Since we can't designate the "null struct" as const, we must find an alternative method to prevent writes to it. The use of that `read_only` macro is pretty clever.