
The Function Is A Lie
The relationship between software and its effects: "functions" vs. functions, multithreading, command buffers, and more.

I recently mentioned, in conversation, a technique I regularly use for user interface animation, which I’ve written about before. It’s not applicable for all animation curves in all scenarios, but it tightly fits design goals for a user interface, it’s simple, it’s low-cost to implement, and it produces robust animation behavior which gracefully adapts to mid-animation changes. Importantly, this technique introduces no new effective codepaths over the equivalent non-animated system, meaning it’s easy to write once and have a strong guarantee of correctness.
It looks like this:
value += (target - value) * rateOne of the responses I received was one with raised eyebrows—“isn’t that just linear interpolation, blending between value and target?”
In one sense, the answer is yes—looking at any “lerp” function will show an identical computation:
F32 Lerp(F32 v0, F32 v1, F32 t)
{
v0 += (v1-v0) * t;
return v0;
}But in another sense, the answer is no. Let’s compare a main loop which produces a linear interpolation animation:
F32 start = 1.f;
F32 value = start;
F32 end = 10.f;
F32 time_in_seconds = 0.f;
F32 dt = 1.f / 60.f;
for(;;)
{
value = Lerp(start, end, time_in_seconds/4.f);
time_in_seconds += dt;
}…with that which produces the exponential animation curve that I use my original snippet to produce:
F32 start = 1.f;
F32 value = start;
F32 end = 10.f;
F32 dt = 1.f / 60.f;
for(;;)
{
value = Lerp(value, end, 1 - pow(2.f, -4.f*dt));
}Assuming value is used to position something on the screen, the end results are dramatically different:

In both cases, I call Lerp every frame. But to produce the linear animation curve, the t used for Lerp changed as time progressed. To produce the exponential animation curve, the t used for Lerp stayed the same, while v0 instead changed.
To understand why I claim the latter is “more robust”, and “does not introduce new effective codepaths”, consider a situation in which end—the target value for the animation—changes during the animation. This commonly arises in user interfaces, where animation is merely intended to show a transition between two well-defined logical states.
In order to properly “reset” the animation in the case of linear animation, there must be a conscious decision on the part of the animation code to “reset”—start, end, and t must be adjusted, and on every frame, that “reset” either happens or not.
In the case of the exponential animation, the codepath is written such that the same computation occurs for all values and all ends. end can simply be written over (perhaps every frame as part of the single animation codepath), rate stays identical, and value’s current state makes no difference—the codepath will operate correctly regardless.
So, in any case, was the original comment about it being “linear interpolation” wrong? Well, no, not really—but the same name being used to refer to the two above animation implementations makes that name not meaningful in this context.
What, then, is meaningful in this context?
Consider another set of functions—just mathematical functions which predict value across frames for each animation style (sweeping along this function is visualized when using these animation styles in rendering).
One looks like this when plotted:

And the other looks like this when plotted:
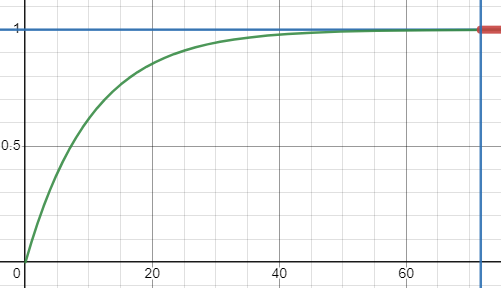
These are the functions that are actually connected to the end effect of the software—they’re what a programmer makes decisions about. How is the thing on the screen actually going to move at the end of the day?
But these are not functions in code—in fact, each can be implemented with the same code function (called differently). Each can be implemented with no additional code functions at all. These are mathematical functions which model the effect of some code.
In the latter case, it’s hopefully clear that this function is produced by aggregating the effects of each individual Lerp. On each frame, yes, it’s a linear interpolation—but the cross-frame effect is an exponential curve.
In the former case, the shape of the value modelling function closely matches Lerp with respect to t, with a fixed v0 and v1. But to claim that therefore Lerp is the same as this mathematical function is an error!
In both cases, the mathematical function which models the software’s effects “slices through” a set of frames. One line of code, in this case performing a single linear interpolation, is not representative of that mathematical function—the mathematical function describes the effect of that code across multiple frames.
I happen to think that—maybe—calling code functions “functions”, knowing that mathematical functions are relevant for programming and are also called “functions”, was a major slip up, bound to cause confusion for decades. (I’m sure that this is only clear in hindsight—I would’ve made the same mistake in a historical context and worse—but I think it’s time to correct the record!)
I’d like to use this example to introduce the point of this post: mathematical models are useful in reasoning about effects, but programming language constructs are just tools to produce physical effects with a computer. They are entirely distinct in nature. The physical effects can follow a track outlined by a mathematical model, but the two are not one in the same.
In my experience, even if that premise flatly stated is accepted, silently merging these two concepts in one’s mental model causes a number of problems. Forcing a mathematical function to be implemented in close relationship with a composition of code functions is often technically inappropriate. Code functions have specific technical constraints, and mathematical functions describing the desired high-level effects of software exist as mathematical entities disconnected from those constraints.
I’ll show this with some examples.
Command Buffers
One clear way in which this distinction between code functions and mathematical functions manifests is by looking at problems in which command buffers are used.
A graphical application implements an overarching mathematical function Program State → Frame Buffer. The application produces a changing grid of pixels as its internal state changes. But the possibilities in implementing that mathematical function concretely are endless, and many of those possibilities do not have obvious maps from code functions to mathematical functions.
Take the following code:
// implements state -> framebuffer
void Draw(ProgramState *)
{
// ...
// draw red rectangle from p0 to p1
DrawRect(R2F32(p0, p1), V4(1, 0, 0, 1));
// ...
}It may be tempting to imagine that DrawRect has a loop that goes and fills out a bunch of pixel values, or if it’s operating the GPU, kicking off some GPU code which does the same. But this is often not how such a function would be implemented in practice, because such an implementation would break technical constraints.
Perhaps doing one rectangle at a time is simply not reasonable for performance, because some work can be done per rectangle batch instead. This cannot be done if the entire per-rectangle drawing codepath is implemented in DrawRect. An entire rectangle batch may eliminate entire swathes of work, if some of those rectangles overlap and occlude others.
It may be inappropriate to do (or organize GPU) pixel-fill work on this thread at all—it may be better to pull rendering work into its own thread(s), and allow logical work for the subsequent frame to begin as the previous frame’s framebuffer is being produced.
Nevertheless, the idea that the program needs some rectangle rendered with these parameters is still important information. But that’s really all this codepath needed to produce: information. A different codepath can consume that information and do further rendering work.
As a result, many practical implementations of DrawRect (or equivalent, or similar) instead simply append to a command buffer—or, a data structure which records (and possibly batches) information pertaining to each draw command. Later, that command buffer is taken as input by a different codepath, which performs the next batch of work relevant to rendering.
That separate rendering codepath can then exist in a different layer within the codebase, be implemented for various backends, run on a different thread, take full advantage of knowledge of the entire frame (rather than having to do rendering work immediately), and so on.
This is another example of the high-level mathematical effect of the software being quite distinct from the shape of the code which programs the machine to produce that effect.
Code Editors and “Replace Range”
(The remainder of this post is for paid subscribers only)